
Linear Regression Cost function derivation

TL;DR
From this post you’ll learn how Normal Equation derivation is performed for Linear Regression cost function.
Introduction
Recently I enrolled in wonderful Machine Learning course by Andrew Ng’s in Stanford. In the Linear Regression section, there was this Normal Equation obtained, that helps to identify cost function global minima. Unfortunately, the derivation process was out of the scope. I found it not quite obvious so I’d like to share it in case someone finds it struggling as well.
There was this post by Eli, which explains the derivation process step-by-step. However, the author performs all the Calculus in vectorized form, which is objectively more complicated that scalar one. I suggest the shorter and easier derivation process here.
Derivation
So, suppose we have cost function defined as follows:
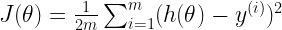
The partial derivatives look like this:

The set of equations we need to solve is the following:

Substituting derivative terms, we get:

To make things more visual, let’s just decode the sigma sign and write explicitly the whole system of equations:

Let us now consider the following matrices:

Thus, the following vector can be calculated:

Now, looking at our matrices and comparing them to the system of equations, we can notice that the system can be rewritten as follows:

Simplifying, we get:

Conclusion
Now that’s it for the day. I tried to explain algebra beneath the Linear regression Normal equation. I think it’s quite important to understand the low-level concepts of algorithms to have a better grasp of the concepts and just have a clearer picture of what’s going on. Until next time, folks. Stay cool and don’t brawl, unless with data.